
Highly accurate protein structure prediction with AlphaFold
回顾总体
经典之作再汇报XD
当前为汇报版直接复制过来,大多内容为口述未放到markdown中,待我有空补充一下
汇报我负责介绍编码器部分,所以下面只有编码器部分
下面是整体结构图
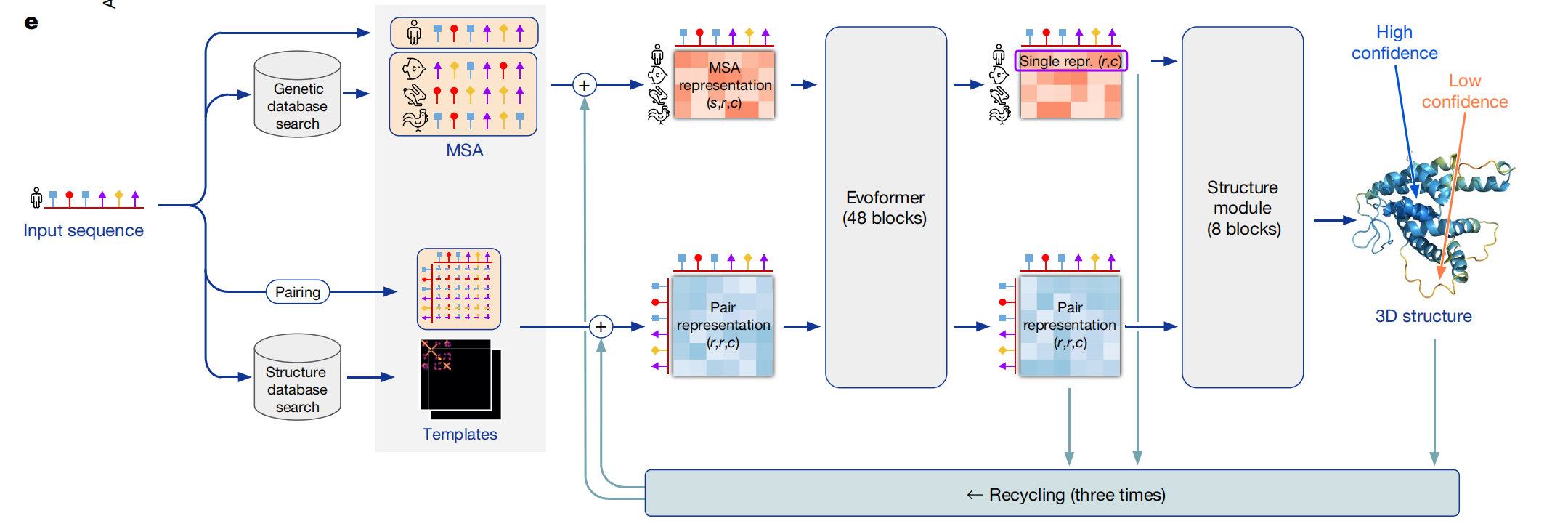
编码器
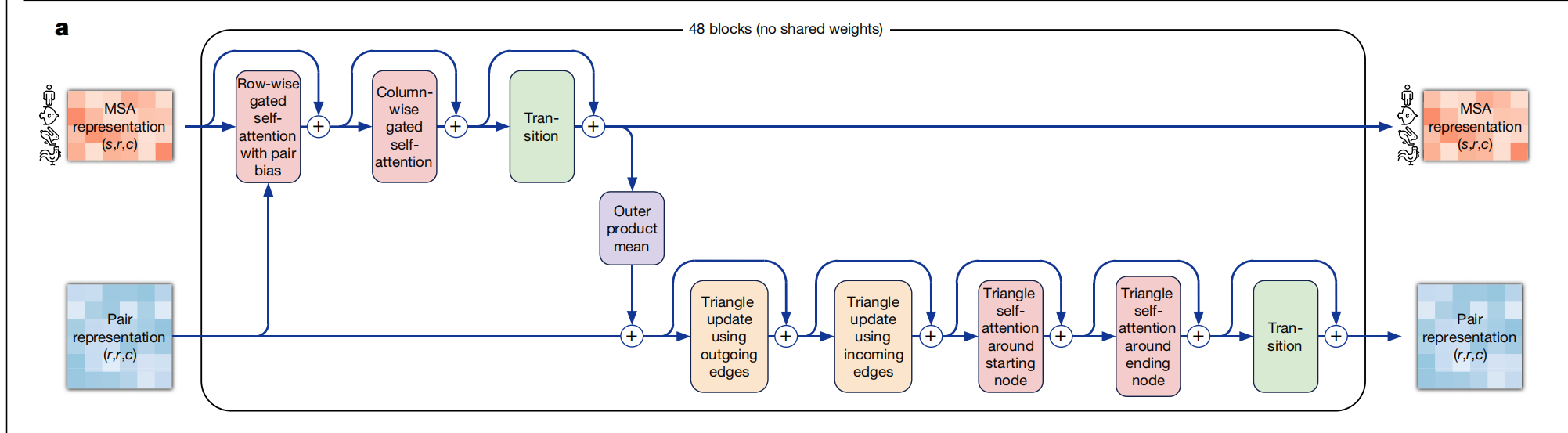
- 多头自注意力机制(行,列)
- MLP
- 残差连接
行多头注意力机制
MSA row-wise gated self-attention with pair bias. Dimensions: s: sequences, r: residues, c: channels, h: heads.
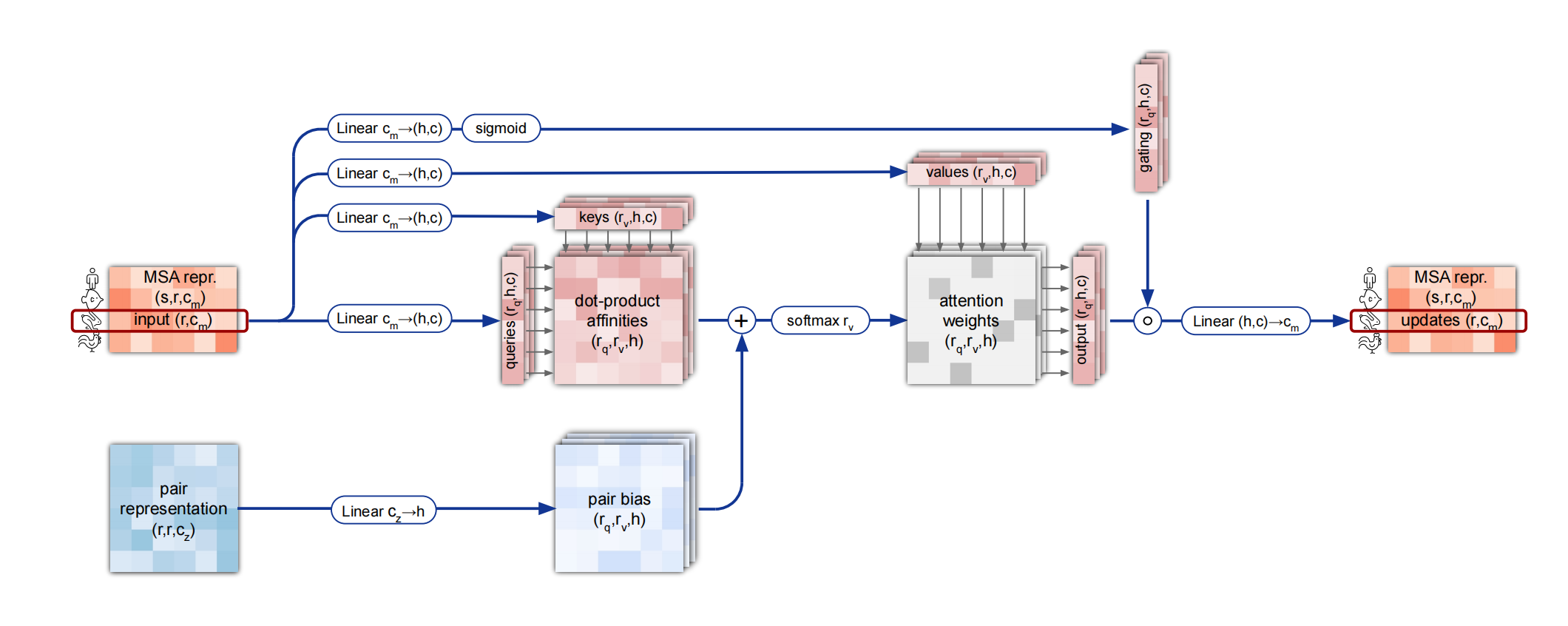
行多头注意力机制

列多头注意力机制
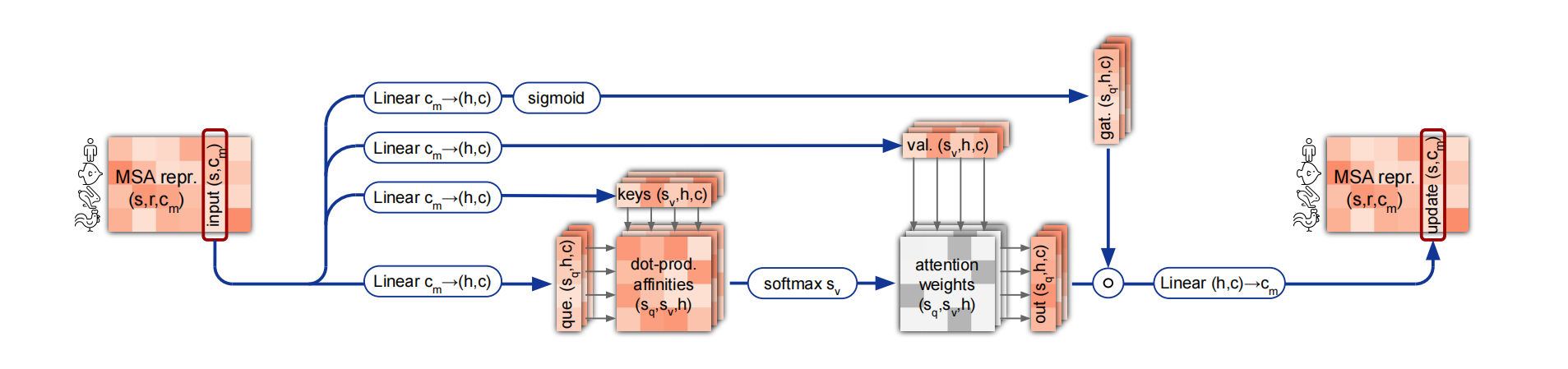
基本与行一样
两个模块分开建模而不是一起,复杂度较低
MLP
在transformer,自注意机制主要是混合不同元素之间的信息
而mlp才是真正信息的提炼
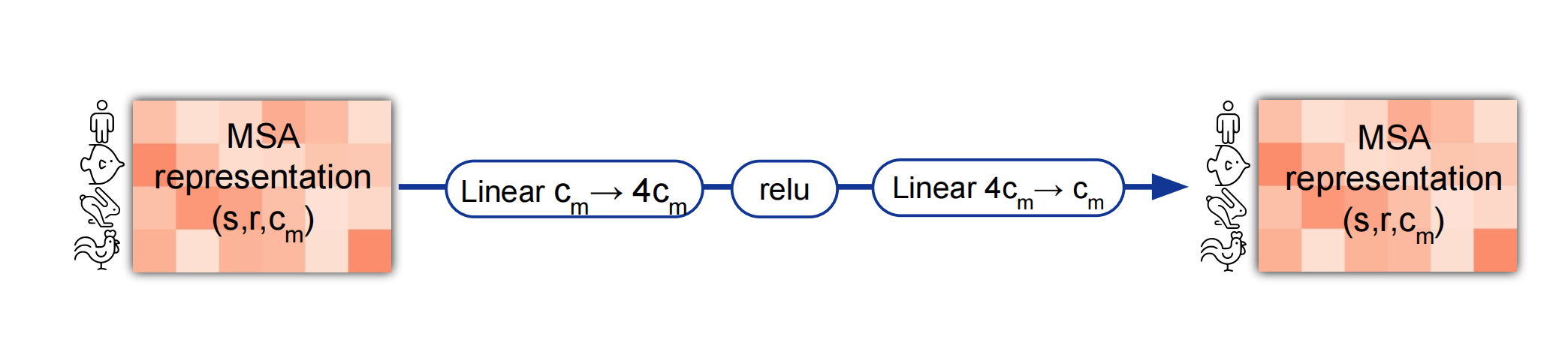
对每个元素通过全连接层投影到原来4倍的大小,再通过Relu激活层投影回原始大小
全连接层的权重对每个元素共享
Out product mean
两个矩阵转为一个向量
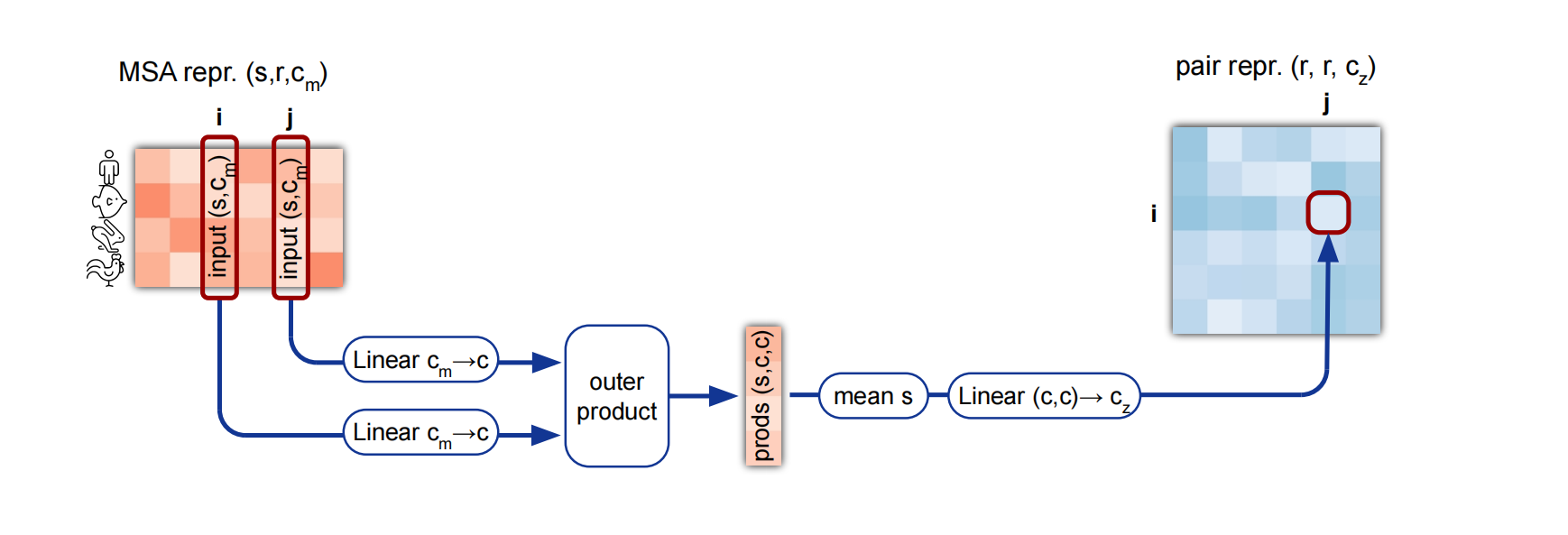
- 全连接层投影到c维
- 做外积转为scc的张量
- 取均值转为(c,c), 拉直投影为
Pair信息的自注意力
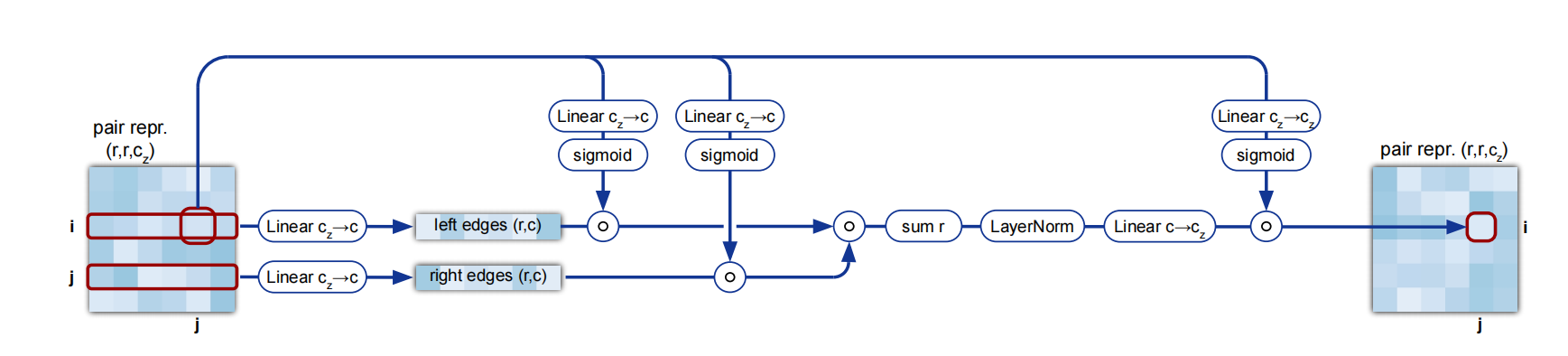

对信息的自注意力
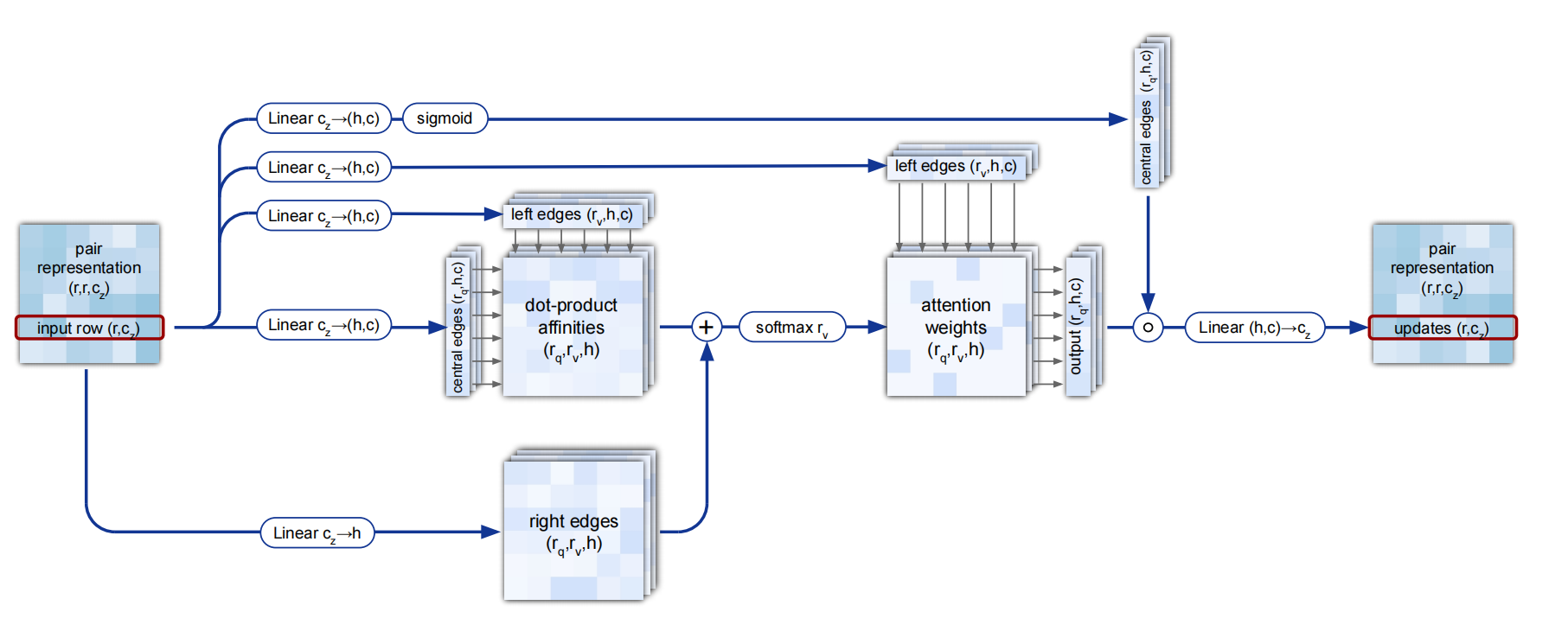
汇报幻灯片
详见这里
题外话
不过现在该读AlphaFold3了